
Used GPUs for AI: The Secondary Market Reshaping Enterprise Compute
The B2B market for used and refurbished data center GPUs, mapped: pricing, players, and the depreciation debate.
The NVIDIA H100's retail price held remarkably steady at $25,000–$40,000 from mid-2024 into early 2026. But the secondary market told a different story—used and refurbished H100s traded as high as $50,000 per GPU during peak scarcity in mid-2024, then dropped sharply as supply normalized. The sticker price was never the real price. The secondary market was.
A parallel market for used and refurbished data center GPUs has quietly become a structural layer of AI infrastructure economics. It lowers the CapEx barrier for neocloud operators building GPU capacity, provides capital recovery for hyperscalers rotating through hardware generations, and creates pricing signals that shape how the entire industry thinks about GPU investment, depreciation, and hardware lifecycle planning. And yet, almost no dedicated coverage of this market exists from an enterprise or infrastructure perspective—most "used GPU" content still targets consumer gamers buying secondhand RTX cards.
This article maps the B2B secondary GPU market: who's selling, who's buying, what hardware costs, and why GPU longevity is one of the most consequential open questions in AI infrastructure economics today.
TL;DR
- The used GPU market is a mature B2B ecosystem with certified ITAD vendors, enterprise resellers, and structured buy/sell processes—not a clearance bin.
- Used A100 pricing spans roughly $7,800–$18,900 depending on SKU and condition, with active turnover across formal and informal channels. Used H100s remain volatile, having swung from $50,000 at peak scarcity to steep discounts as supply increased.
- The GPU depreciation debate is live and consequential: Amazon shortened server useful lives in 2025 while Meta extended them in the same quarter. Michael Burry estimates ~$176 billion in understated depreciation across the industry. Real-world evidence from Azure, CoreWeave, and hyperscaler VM retirements suggests GPUs retain economic value for 5–7+ years.
- For many inference and fine-tuning workloads, the relevant metric is cost per completed task, not cost per hour—and used A100s often win that math against newer hardware at 2–3x the price.
- The secondary market will grow as hyperscaler GPU spend exceeds $300 billion annually and NVIDIA's annual release cadence (Hopper → Blackwell → Rubin → Rubin Ultra) accelerates fleet rotation cycles.
What Is the Secondary GPU Market?
The secondary GPU market is the B2B ecosystem for buying and selling used and refurbished data center GPUs—A100s, H100s, H200s, and the server systems that house them. It is distinct from the consumer market for gaming GPUs. The participants, price points, and transaction structures are entirely different.
The supply side is dominated by hyperscalers rotating out older GPU fleets as they upgrade to newer generations. When AWS, Google, or Azure deploy Blackwell-generation hardware, the Hopper and Ampere systems they're replacing don't disappear—they enter the secondary market through IT Asset Disposition (ITAD) vendors or direct resale channels. Enterprises consolidating or shutting down AI projects contribute additional supply, as do Bitcoin miners who deployed GPUs for rendering or AI workloads and are now evaluating whether to rotate into newer hardware or exit GPU operations entirely.
The demand side is led by neocloud operators building GPU capacity at lower cost to end users than hyperscalers charge. Roughly one-third of AI workloads run on neoclouds rather than hyperscalers, and many of these operators build capacity using a mix of new and used hardware. (For a deeper look at the neocloud ecosystem, see our explainer on neocloud operators and the GPU cloud providers powering AI.) Smaller enterprises, research institutions with budget constraints, and companies in regions with limited access to new GPU supply also buy used. The common thread is that buyers need GPU compute but either can't afford, can't wait for, or don't need the absolute latest generation.
The intermediaries make the market work. ITAD vendors like Procurri and Bitpro specialize in acquiring, testing, and reselling used GPUs from hyperscalers and large enterprises. Enterprise resellers like Alta Technologies—with 30+ years in the custom server industry—buy and sell used NVIDIA DGX servers and individual GPUs, running multi-point inspections and offering warranties on refurbished units. SellGPU and exIT Technologies handle both the buy and sell side, with R2v3 certification (the responsible recycling standard) and data sanitization compliance.
The distinction between "used" and "refurbished" matters economically. Used implies as-is from a prior deployment—the buyer assumes more risk. Refurbished implies the hardware has been tested, certified, and potentially comes with a warranty. The price difference is meaningful: refurbished H100s consistently sell for 15–25 percentage points more than used counterparts, creating real arbitrage opportunities for resellers who can acquire, test, and certify hardware at scale.
This market is not adversarial. It functions as a natural off-take channel for hyperscalers—they recover capital from older hardware while neoclouds get discounted GPUs. The relationship is symbiotic, and as one industry practitioner noted at the 2026 PTC Conference, "ITAD relationships will become more important as hardware supply tightens."
Current Used GPU Pricing—A100, H100, and the Generation Gap
Concrete pricing data is the most requested and least available information in the secondary GPU market. Public GPU pricing is a snapshot that mixes reseller asks, refurbished inventory, and marketplace listings—and private deals can clear materially lower. With that caveat, here's what the market looks like as of early 2026.
NVIDIA A100—The Most Liquid Used GPU
The A100, released in May 2020, is roughly six years old and remains one of the most actively traded enterprise GPUs on the secondary market. Visible commercial listings run from roughly $7,800 for A100 40GB refurbished units to about $18,900 for an A100 80GB PCIe card. Private or distressed sales can clear lower. A used Gigabyte 8×A100 HGX baseboard was listed on eBay for about $14,500, showing that partial-system and pull-tested inventory moves through informal channels alongside formal ITAD pipelines.
Rather than calling the market "flooded," it's more accurate to say the secondary channel shows sustained two-sided activity: dedicated resellers, ITAD firms, and marketplace listings all point to active turnover in A100 inventory. Purchase prices for used A100s may decline another 10–15% through 2026 as more enterprises upgrade to Blackwell-generation hardware.
Cloud rental comparison: A100 rates range from roughly $1.29–$3.43/hr depending on provider, making the buy-vs-rent breakeven math highly dependent on utilization rates.
The A100 40GB variant is best suited for LoRA/QLoRA fine-tuning of 7B–13B parameter models and inference on quantized models. The 80GB version extends to 13B–65B models, multiple simultaneous models, and larger batch sizes.
NVIDIA H100—Volatile and Regime-Dependent
The H100 (released March 2023) has experienced the most dramatic secondary market pricing volatility of any data center GPU. Used and refurbished units traded as high as $50,000 per GPU during mid-2024 scarcity, then dropped sharply as supply increased and buyer power returned. Retail prices held steady at $25,000–$40,000 through this period, masking the secondary market turbulence underneath.
Cloud rental pricing followed a similarly dramatic arc—dropping from roughly $7–$10/hr at launch in 2023 to about $2–$4/hr by late 2025, with some providers dipping below $2/hr on spot. Silicon Data recorded a short-lived rebound in early 2026, so the trajectory has been volatile rather than one-way down. AWS reportedly cut H100 pricing by about 44% in June 2025, helping trigger a broader market reset.
At the server level—the typical B2B purchase unit—a used H100 server (8-GPU) trades at roughly $150,000–$180,000. Compare that to a new B300 server at approximately $500,000. Refurbished GPU servers from vendors like Alta Technologies and NewServerLife offer 40–70% savings over new OEM systems with warranties and tested components. (For context on how these economics fit into the broader GPU-as-a-Service model, see our breakdown of the GPUaaS business model.)
The Cost-Per-Task Argument
For many workloads—inference, fine-tuning, batch processing—the A100 delivers comparable results to the H100 at roughly half the cost. The relevant metric is cost per completed task, not cost per hour. An A100 at $1.49/hr may deliver better total economics than an H100 at $2.99/hr for inference workloads where the H100's additional performance doesn't proportionally reduce completion time. Buyers who optimize for cost per hour alone are often overpaying for capabilities their workloads don't need.
A Note on Component Costs and Tariffs
Used GPU servers aren't plug-and-play in every case. Memory and storage often need refreshing, and those component markets have tightened. DDR4/DDR5 and server SSD pricing rose sharply from late 2025 into early 2026 as AI demand strained supply, with some analysts projecting server-memory prices could roughly double by 2026. HBM pricing and availability tightened as well, as production shifted toward AI-grade memory. These component costs can erode the savings advantage of buying used hardware if the server needs significant refreshes.
Additionally, 2025 tariff policy increased uncertainty and created upward pricing pressure for some GPU and server supply chains, with outside estimates often clustering in the 20–40% range for affected categories.
The GPU Depreciation Debate—How Long Do Data Center GPUs Actually Last?
GPU longevity is one of the most consequential open questions in AI infrastructure economics. The answer directly determines the secondary market's value proposition, the accuracy of hyperscaler earnings, and the viability of the "value cascade" model that the entire used GPU thesis depends on. Right now, the industry can't agree on the answer.
The Accounting Backdrop
Hyperscalers extended server depreciation schedules from 3–4 years to 5–6 years between 2020 and 2024. AWS led in January 2020, extending from 3 to 4 years. By 2023, all three major hyperscalers (AWS, Google, Azure) had normalized on 6-year schedules.
Then, in early 2025, the consensus fractured. Amazon shortened a subset of server useful lives from 6 to 5 years, citing "the increased pace of technology development, particularly in the area of artificial intelligence and machine learning"—a $677 million net income reduction for the first nine months of 2025. Meanwhile, Meta extended to 5.5 years in the same quarter, booking a $2.9 billion depreciation reduction. Same technology, opposite accounting conclusions. Among neoclouds, Lambda Labs depreciates over 5 years, Nebius over 4, and CoreWeave uses an aggressive 6-year schedule despite being exclusively AI-focused.
The divergence reveals something important: depreciation is being used as an active earnings management lever, not purely as an engineering assessment of hardware lifespan.
The Burry Argument
Investor Michael Burry has taken the short-lifecycle thesis to its sharpest conclusion. He claims hyperscalers are overstating earnings by depreciating hardware over 5–6 years when NVIDIA's chip cycle implies 2–3 year economic life. His estimate: ~$176 billion in understated depreciation across the industry between 2026 and 2028. He has backed this position with put options on NVIDIA and Palantir.
The logic is straightforward: if a new GPU generation ships every year (Hopper in 2022, Blackwell in 2024, Rubin in 2026, Rubin Ultra in 2027), and each generation offers substantial performance and efficiency gains—Blackwell offers up to 25× better energy efficiency than Hopper for specific inference workloads—then older hardware becomes economically obsolete faster than a 5–6 year schedule assumes.
The Counter-Argument—The Value Cascade
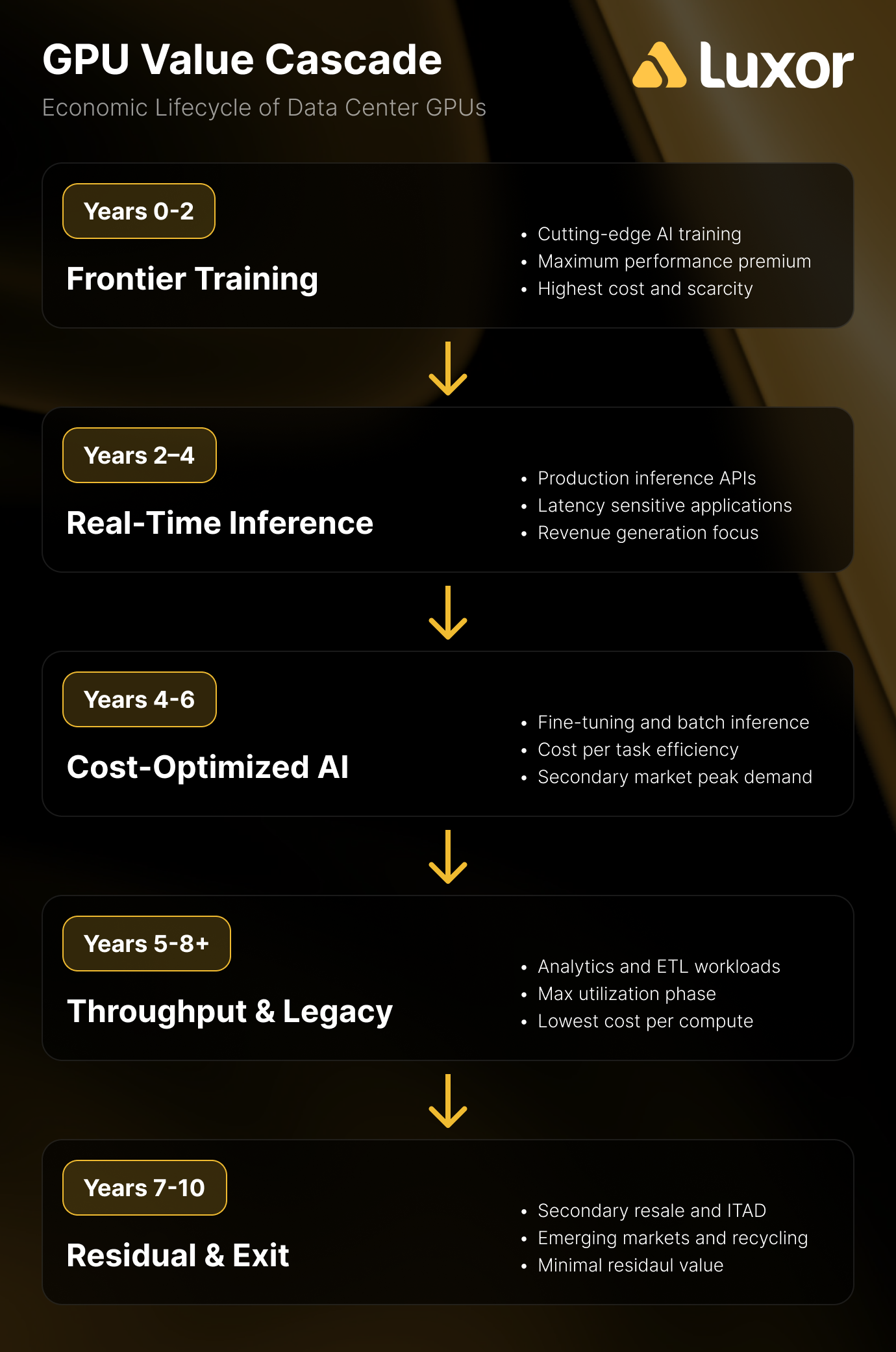
The counter-argument isn't that GPUs don't lose frontier capability. They do. It's that frontier capability isn't the only source of economic value. The value cascade model, proposed by theCUBE Research and supported by real-world deployment data, maps GPU economic life through three phases:
- Years 1–2: Frontier model training—the highest-value, most demanding workloads
- Years 3–4: High-value real-time inference—GPUs no longer train frontier models but run production inference at scale
- Years 5–6: Batch inference and analytics—throughput-oriented workloads where cost per task matters more than latency
Real-world evidence supports longer useful lives than the 2–3 year skeptic estimate. Azure retired K80/P100/P40-powered VMs in August/September 2023—GPUs launched between 2014 and 2016, implying 7–9 year useful service lives. Azure retired V100-powered NCv3-series VMs in September 2025, approximately 7.5 years after the V100's launch. The NVIDIA T4, released in September 2018, still generates rental revenue at ~$0.15/hr on Vast.ai more than 7 years later. And CoreWeave's H100s from 2022 contract expirations were immediately rebooked at 95% of original pricing.
Recent commentary from major industry players reinforces the longer-lifecycle thesis. At NVIDIA GTC 2026, CoreWeave CEO Michael Intrator described a future where operators "pair older GPUs to handle some workloads while the leading edge tech/GPUs will focus on leading edge workloads," adding that the industry needs to "milk all the value that we can to invest in the next wave." Gavin Baker of Atriedes Management, speaking at the same event, went further: the disaggregation of inference will allow further optimization of older GPUs, and "the 4–5 year useful lives may be more like 8–10."
Software-level innovations strengthen this argument. GPU fractioning—running multiple workloads on a single GPU—and advanced scheduling are extending the useful throughput of older hardware. At GTC 2026, the Danish Centre for AI Innovation demonstrated that GPU fractioning on B200s increased inference token throughput by ~75%, while Run:AI's orchestration yielded up to 10× GPU availability and 5× utilization improvements. If software can squeeze 5× more utilization out of existing hardware through better scheduling and resource management, the economic case for keeping older GPUs in production gets meaningfully stronger.
The Honest Answer
Nobody knows yet. The GPU lifecycle for AI workloads doesn't have enough historical data to resolve the debate conclusively. Meta's published data on H100 reliability—148 GPU failures out of 419 total disruptions across 16,384 H100 GPUs over 54 days of Llama 3 405B training, implying roughly a 9% annualized failure rate under heavy utilization—adds another variable. What we do know is that legacy GPUs retain meaningful economic value far longer than the "worthless after next generation" framing suggests. The market data and deployment evidence both point toward 5–7+ years of useful economic life, with the exact duration depending on workload mix, failure rates, and the pace of software optimization.
Why the Secondary GPU Market Matters for AI Infrastructure
The secondary GPU market isn't an afterthought or a niche for bargain hunters. It's a structural component of AI infrastructure economics that directly affects CapEx planning, neocloud viability, and hardware lifecycle strategy.
Neoclouds are the primary demand driver. With roughly one-third of AI workloads running on neocloud operators rather than hyperscalers, the CapEx math matters enormously. A used H100 server at $150,000–$180,000 versus a new B300 server at $500,000 represents a fundamentally different business case—and for many neocloud operators, that difference determines whether they can build capacity at all.
The workload matching argument is underappreciated. Not all AI workloads need the latest generation hardware. Many inference and fine-tuning workloads run well on A100s or even older GPUs. Morgan Stanley's Mark Edelstone noted at GTC 2026 that "inference is still very early days" and pointed to edge deployments—which don't require frontier hardware—as a coming wave. OpenAI's Sachin Katti acknowledged that while homogeneous infrastructure is operationally simpler, "shifting workload economics likely necessitate heterogeneous fleets"—a direct case for mixing new and used hardware. The relevant question isn't "is the H100 better than the A100?"—it usually is. The relevant question is whether the H100's performance advantage justifies 2–3× the cost for a specific workload. For many B2B buyers, the answer is no.
Capital efficiency and time-to-value. The secondary market offers immediate availability versus months-long wait times for new hardware. For companies that need to deploy AI compute quickly, time-to-value often matters more than having the absolute latest generation.
The hyperscaler symbiosis. Hyperscalers rotating out older GPU fleets need off-take channels to recover capital. ITAD vendors and the secondary market provide this, improving capital recovery for hyperscalers while supplying neoclouds with discounted hardware. This is not a zero-sum market—it's a capital recycling loop that benefits both sides.
The Bitcoin miner angle. Miners who deployed GPU infrastructure for rendering or AI compute may find themselves on the sell side of this market as they evaluate whether to rotate into newer hardware or exit GPU operations. Understanding secondary market pricing and timing is directly relevant to exit strategy and capital recovery planning.
What Could Change—Risks and Open Questions in the Used GPU Market
The secondary market's growth trajectory is not guaranteed. Several forces could accelerate depreciation, compress resale values, or disrupt the supply-demand dynamics that make used GPUs attractive today.
NVIDIA's accelerating release cadence is the most direct risk. The shift to an annual product cycle—Hopper (2022), Blackwell (2024), Rubin (2026), Rubin Ultra (2027)—compresses the window in which any generation is "frontier." Each new generation floods the secondary market with previous-gen hardware. If supply cascades faster than demand absorbs it, resale values compress. Jensen Huang's GTC 2026 keynote reinforced this trajectory: Vera Rubin promises 40 million times more compute than a decade ago, requires 100% liquid cooling, and reduces installation time from two days to two hours. When new hardware is that much better and that much easier to deploy, the floor under older hardware gets less certain.
Custom AI ASICs are a theoretical threat to the value cascade, but pricing hasn't yet validated the disruption case. Hyperscalers are deploying custom inference chips (AWS Inferentia/Trainium, Microsoft Maia, Meta MTIA) designed to outperform older GPUs on specific inference workloads. In theory, a purpose-built inference ASIC should undercut a general-purpose GPU on total cost of ownership. In practice, early pricing on custom silicon has landed roughly at parity with new GPU-based builds, which limits the cost advantage over used GPUs as well. AI ASICs remain small-scale today (Cerebras is the most notable) and haven't yet disrupted secondary GPU demand, but they're worth monitoring as production scales.
Market saturation is a math problem. At $300+ billion in annual hyperscaler GPU spend and ~$35,000 average per GPU, the industry is purchasing millions of GPUs annually. If all of these cascade to secondary markets on a 3–4 year cycle, the volume of used hardware could outstrip demand and compress resale values. OpenAI's Katti noted that the company tripled compute from 2024 to 2025, targeting up to 5 gigawatts this year and ramping toward 30 gigawatts over the next few years. The scale of what's being deployed today is the scale of what hits secondary markets in 2028–2030.
Component inflation narrows the savings spread. Memory and storage price increases can erode the cost advantage of buying used. Used GPU servers that need DIMM or SSD refreshes at inflated component prices become less attractive compared to new systems that ship complete. Katti also flagged the tension between "data center hardware lifecycles of 5–6 years" and AI's rapid change cycle—co-designing for both performance and flexibility is an unsolved challenge.
These risks are real, but none of them invalidate the secondary market. They create volatility and uncertainty in GPU resale values—which is exactly why understanding the market matters for infrastructure buyers and sellers alike.
The Most Expensive GPU Is the One Deployed Against the Wrong Workload
The secondary GPU market is not a niche. It's a structural component of AI infrastructure economics that affects CapEx planning, depreciation accounting, neocloud viability, and hardware lifecycle strategy across the industry.
For companies buying GPU compute in volume, understanding used-versus-new economics is now a core competency—not an optional cost optimization. The ITAD ecosystem is mature, the pricing data is increasingly transparent, and the range of certified vendors and structured buy/sell processes has moved well beyond the "Wild West" phase.
The GPU longevity question remains unresolved, but the weight of evidence—Azure's 7–9 year GPU service lives, CoreWeave's 95% rebooking rates, T4s still generating rental revenue after 7+ years, and public statements from CoreWeave's CEO about pairing older GPUs with frontier hardware for workload-specific optimization—points toward longer useful lives than the 2–3 year "worthless after next generation" narrative suggests. Companies that plan around the value cascade—training → inference → batch—will extract more value from their GPU investments than those that treat every hardware generation as disposable.
The market is evolving fast. Pricing, supply dynamics, and the competitive landscape between new and used hardware will look different in 12 months. The most expensive GPU isn't the one with the highest sticker price—it's the one deployed against the wrong workload at the wrong point in the hardware cycle. The secondary market exists because the industry is learning that lesson in real time.

Hashrate Index Newsletter
Join the newsletter to receive the latest updates in your inbox.








{kind=link}